Sharing information between connected and autonomous vehicles (CAVs) fundamentally improves the performance of collaborative object detection for self-driving. However, CAVs still have uncertainties on object detection due to practical challenges, which will affect the later modules in self-driving such as planning and control. Hence, uncertainty quantification is crucial for safety-critical systems such as CAVs. Our work is the first to estimate the uncertainty of collaborative object detection. We propose a novel uncertainty quantification method, called Double-M Quantification, which tailors a moving block bootstrap (MBB) algorithm with direct modeling of the multivariant Gaussian distribution of each corner of the bounding box. Our method captures both the epistemic uncertainty and aleatoric uncertainty with one inference based on the offline Double-M training process. And it can be used with different collaborative object detectors. Through experiments on the comprehensive CAVs collaborative perception dataset, we show that our Double-M method achieves up to 4.09 times improvement on uncertainty score and up to 3.13% accuracy improvement, compared with the state-of-the-art uncertainty quantification. The results also validate that sharing information between CAVs is beneficial for the system in both improving accuracy and reducing uncertainty.
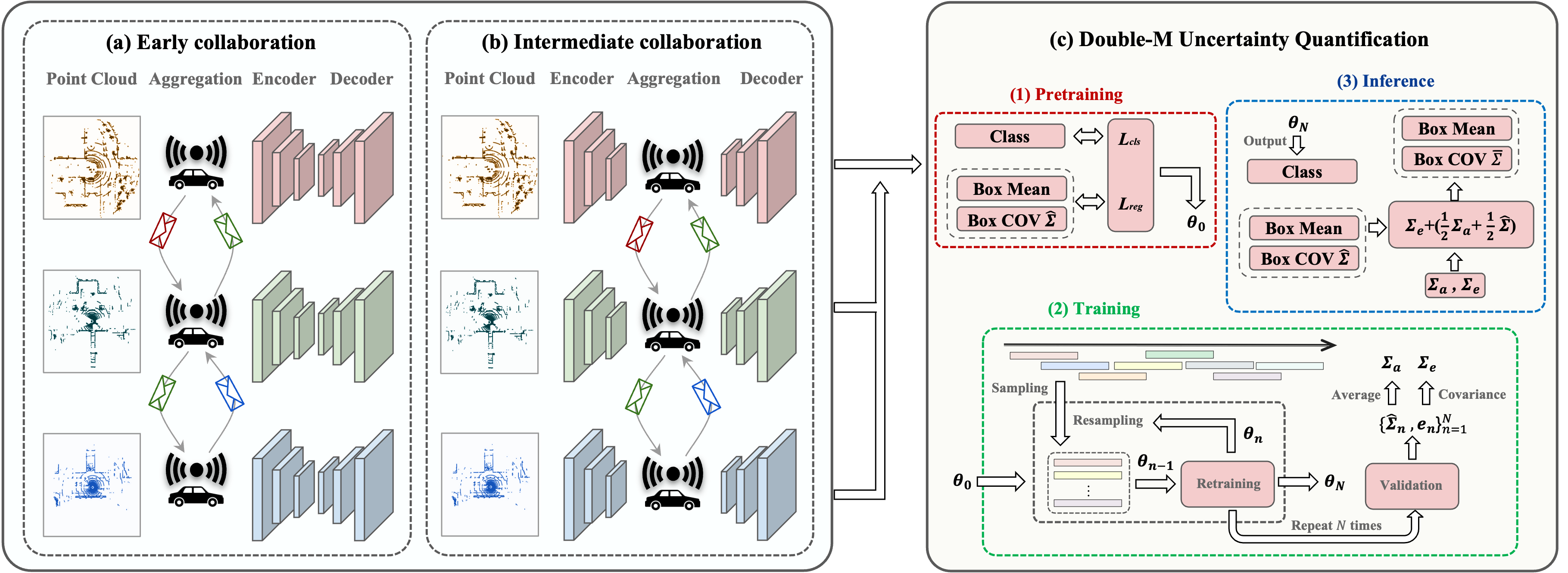
Implementation of our Double-M Quantification method on collaborative object detection. (a) Early collaboration shares raw point cloud with other agents, and (b) intermediate collaboration shares intermediate feature representations with other agents. (c) Double-M Quantification method estimates the multi-variate Gaussian distribution of each corner. Our Double-M Quantification method can be used on different collaborative object detection. During the training stage, Double-M Quantification tailors a moving block bootstrapping algorithm to get the final model parameter, the average aleatoric uncertainty of the validation dataset and the covariance of all residual vectors for epistemic uncertainty. During the inference stage, we can combine the aforementioned two covariance matrix and the predicted covariance matrix from the object detector to compute the final covariance matrix.
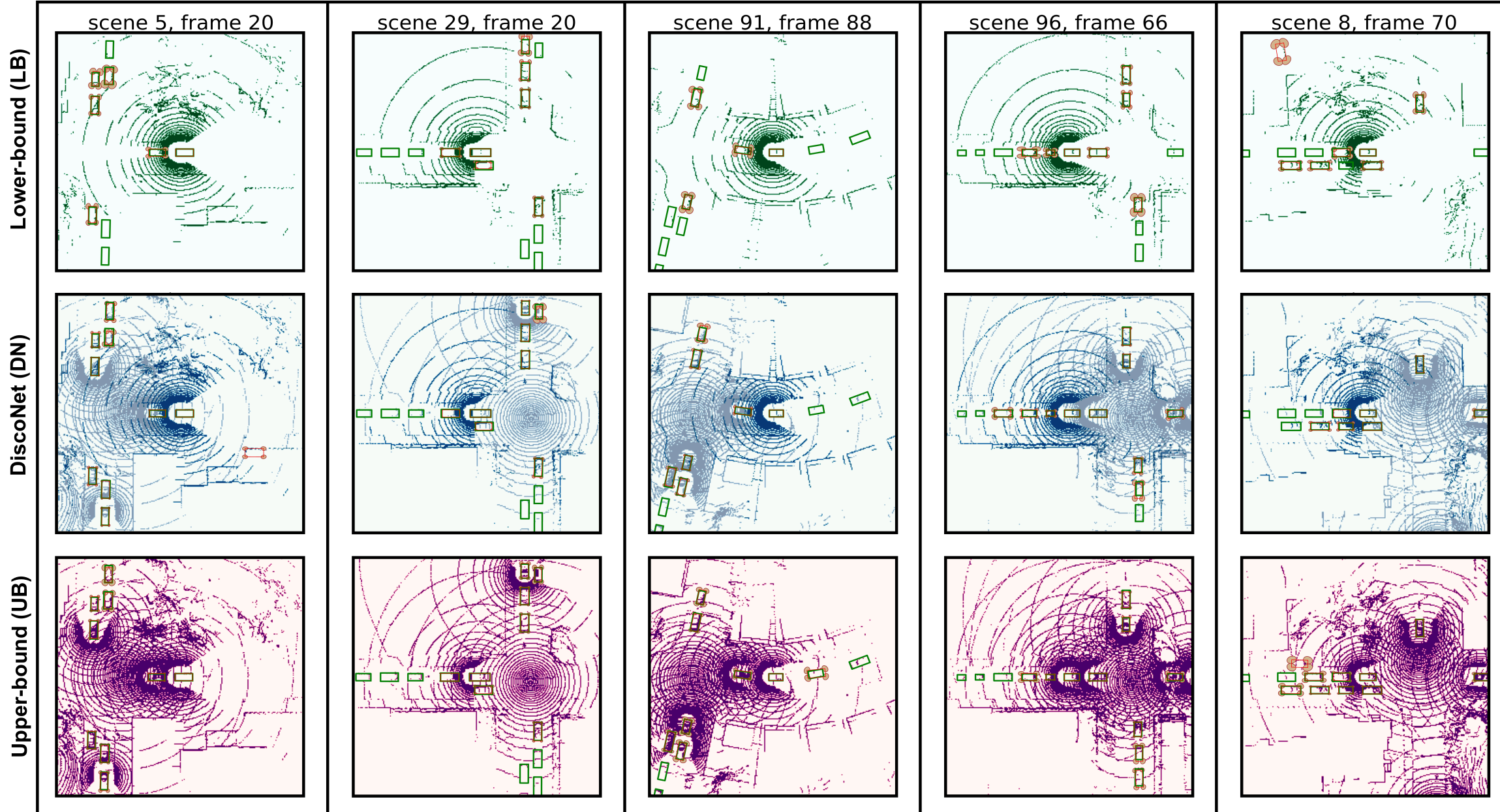
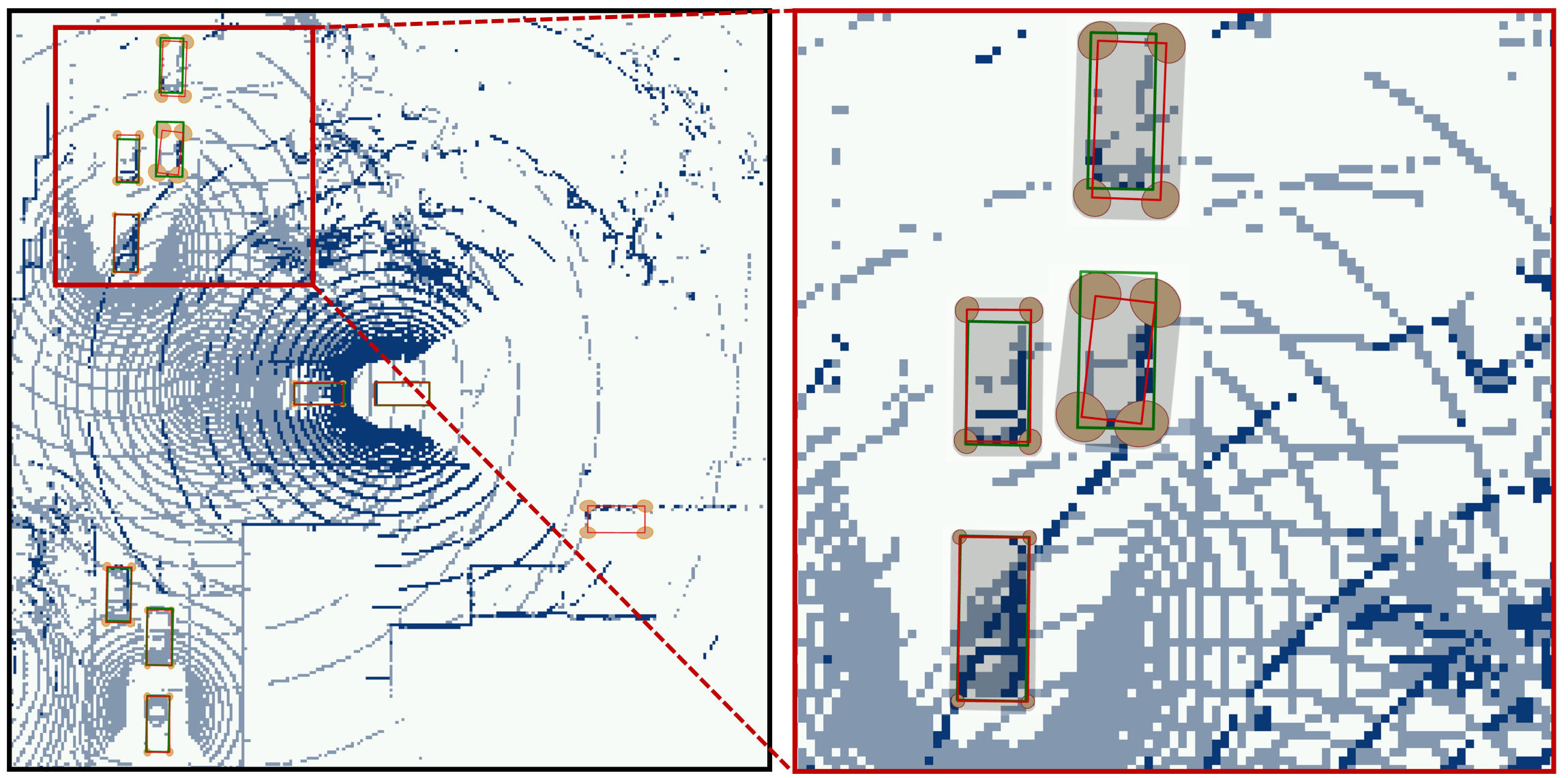
Visualization of our Double-M Quantification results on different scenes of V2X-Sim [1]. The results of LB, DN, and UB are respectively shown in the first, second, and third row. Red boxes are predictions, and green boxes are ground truth. Orange ellipse denotes the covariance of each corner. We can see our Double-M Quantification predicts large orange ellipses when the differece between the red bounding box and the corresponding green bounding box is huge, which means our method is efficient.
@article{Su2022uncertainty,
author = {Su, Sanbao and Li, Yiming and He, Sihong and Han, Songyang and Feng, Chen and Ding, Caiwen and Miao, Fei},
title = {Uncertainty Quantification of Collaborative Detection for Self-Driving},
year={2023},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)}
}