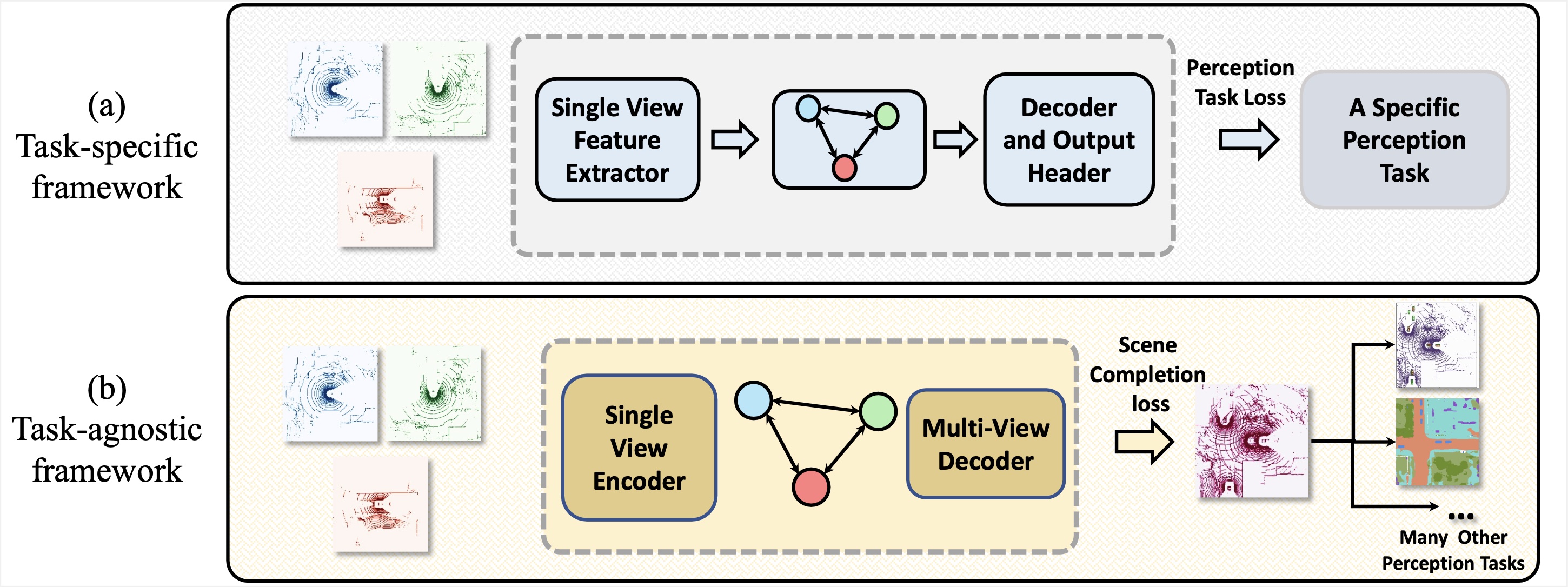
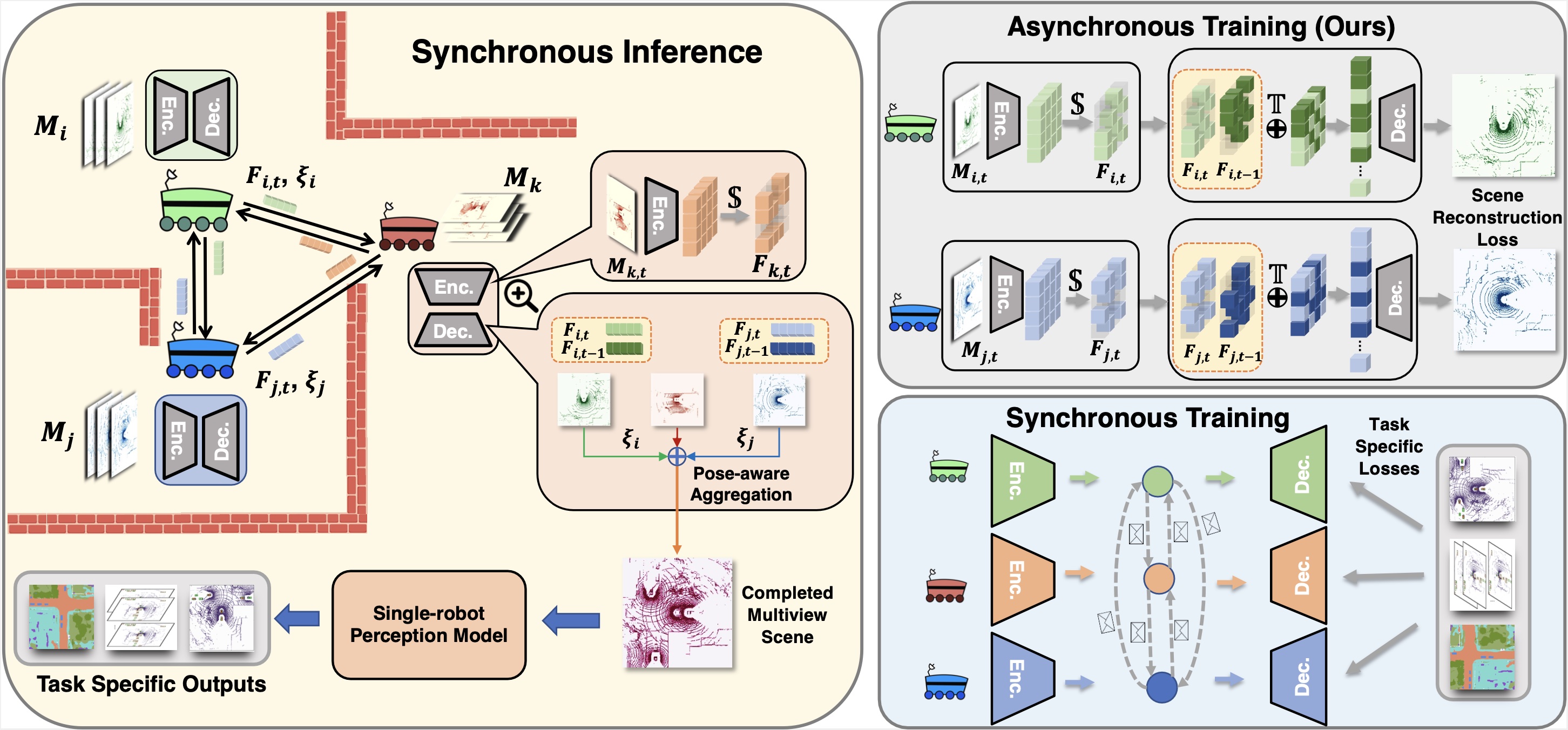
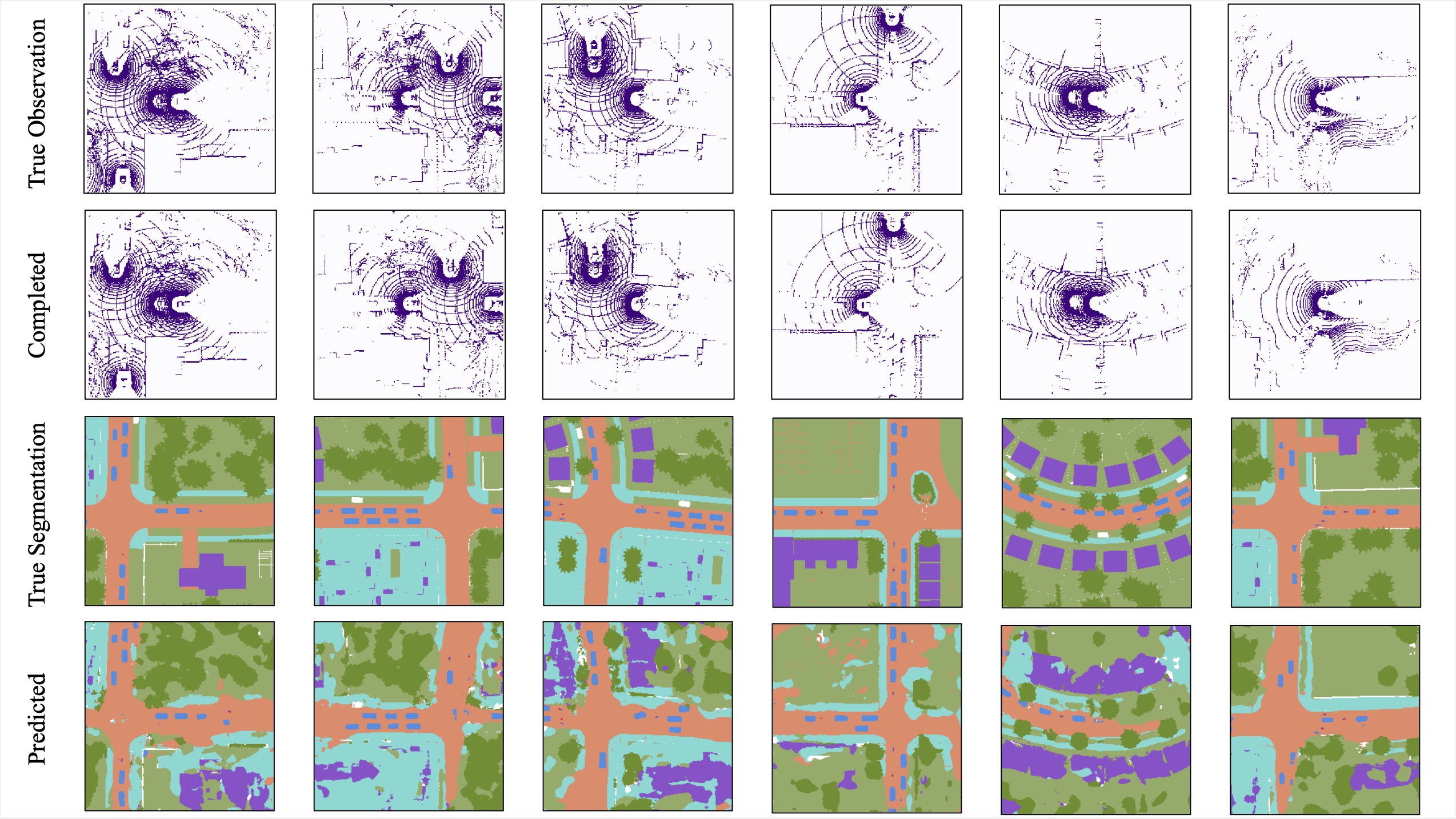
The scene is completed through multi-robot collaboration.
The completed scene can be directly used in any perception without fine-tuning.
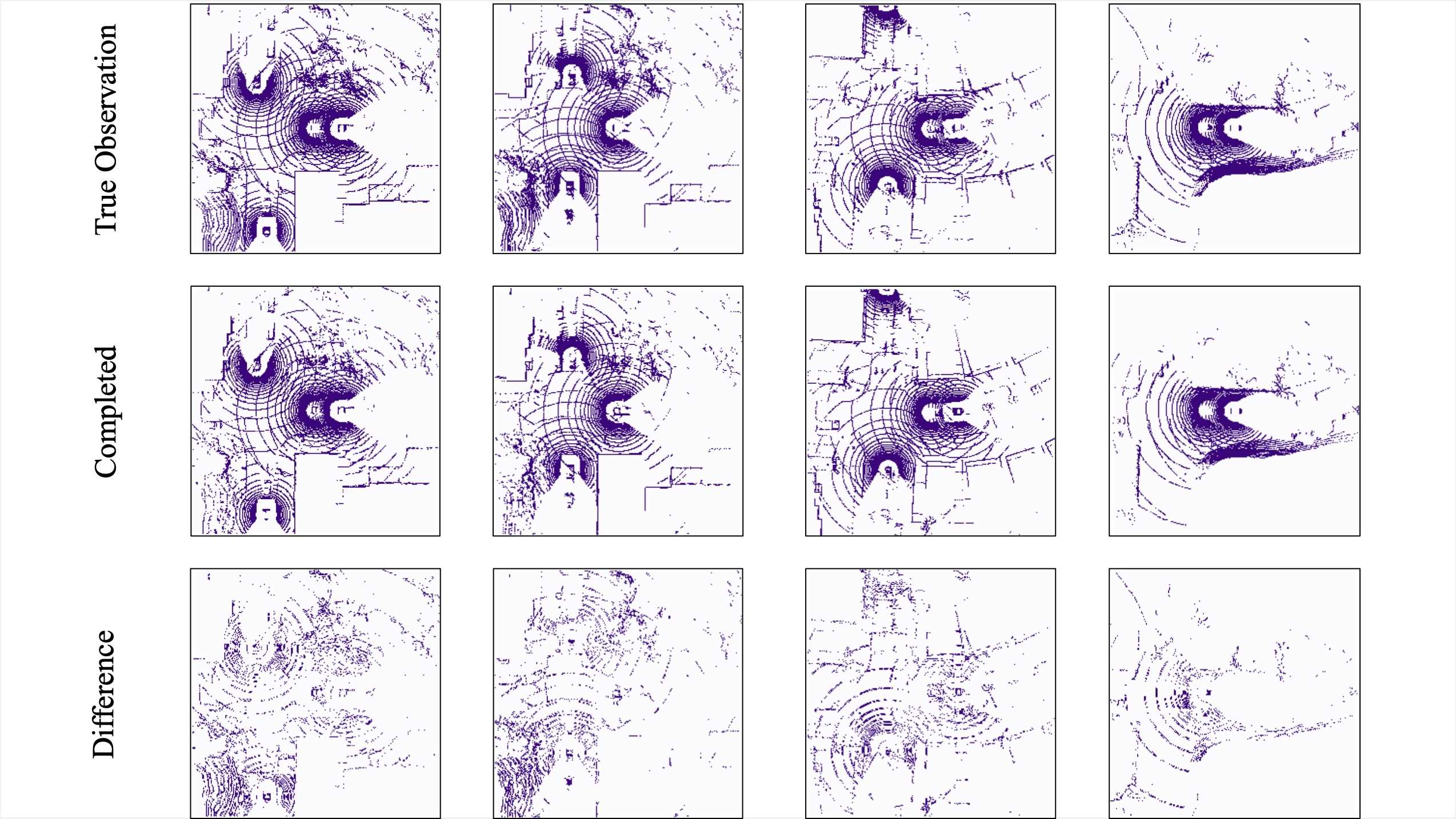
Individual reconstruction

Scene completion

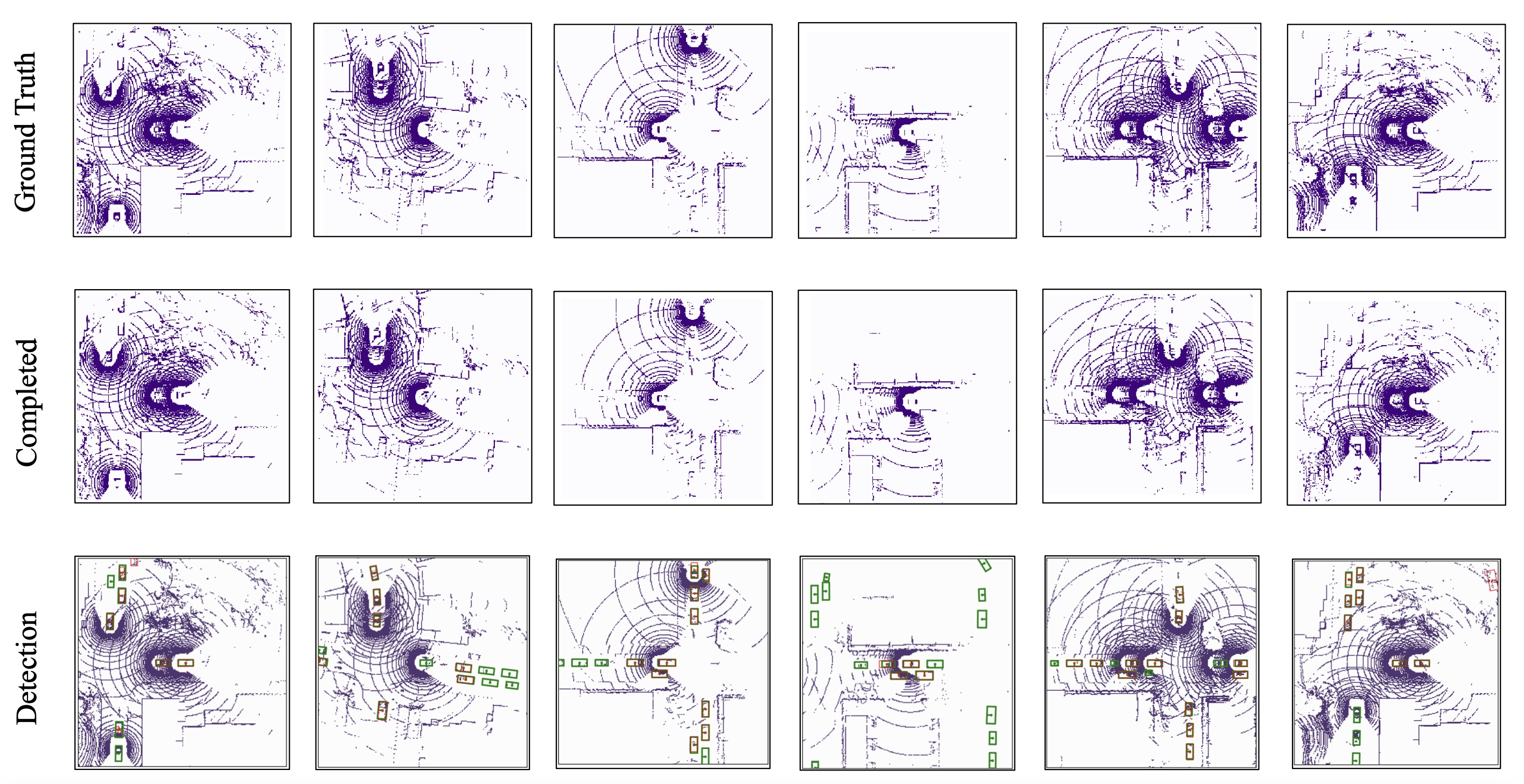
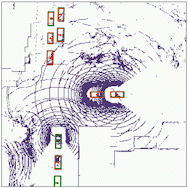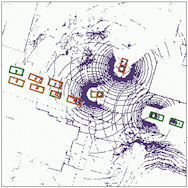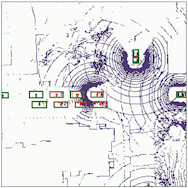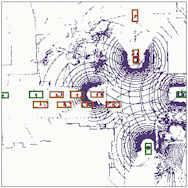
Object detection
Semantic segmantation
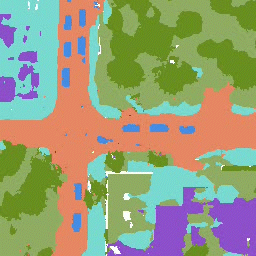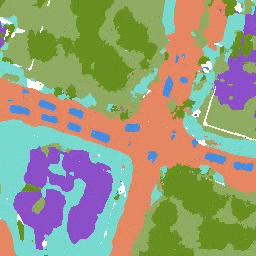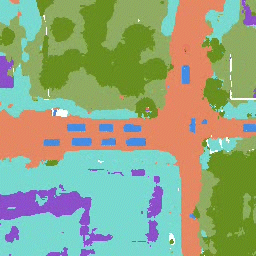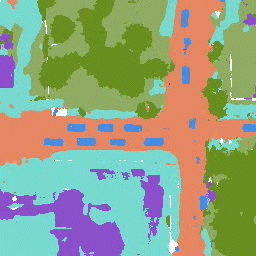

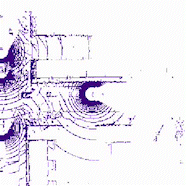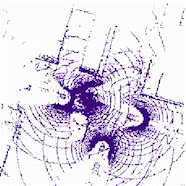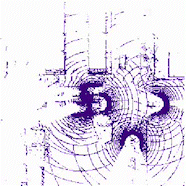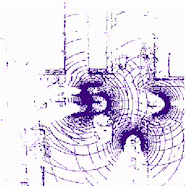
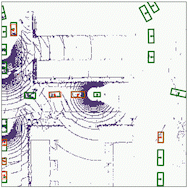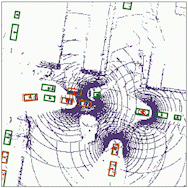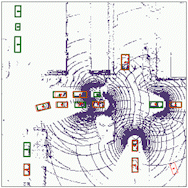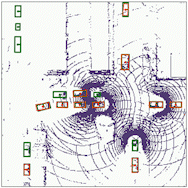

The results for object detection and semantic segmantation are obtained by directly feeding the completion output to singe-agent perception models without any fine-tuning. For object detection, the red boxes are predicted bounding boxes, and the green boxes are the ground truth.